文字数:5300字前後
その昔、新聞を切り抜いてスクラップする人に憧れていた…
こんばんは!まるく堂です!
昔、「新聞記事を切り抜いてスクラップとして集めている人」に憧れていました。

テレビドラマなんかでもありますよね?
例えば、老齢の元刑事が退職後も何かの事件を追ってて、それに関連した何百、何千もの記事を
↓こんな感じのファイルとかノートに挟んでて…

同じく事件を追う主人公がその年輩の元刑事の家を訪ねて行き、
老刑事が何かのヒントをきっかけに「ああ、そう言えば…」と今まで集めた新聞記事がごっそり入ったファイルを取り出して「見てくれ、これだ!この記事!」と主人公に見せるシーンとかありますよね?

そういうのを見る度に「おお!カッコイイ!」と思っちゃうんですよね。
これまでずっと地道に歩んできた努力が報われる瞬間って言うんですかね?
こうして事件を解決するためのバトンが主人公に渡されるワケですよ!
まあ…でもせっかく集めたのに、
その後、犯人に殺されちゃったりしますけど…

(↑何のドラマだよ…)
でも、そのスクラップですが…
自分にはとてもマネできません…
もちろん、昔やりましたよ!チャレンジした事はあるんですよ!
ただ、長続きしませんでした…
新聞のスクラップって作るのが結構面倒くさいんですよ。
まずは新聞からその記事を上手に切り取らなければいけません。
そして親から「ああ、何で切ったんだ!!まだ読んでなかったのに…」と言う
冷たい視線をかいくぐり…

裏面にのりを塗ってノートに貼り付けるけど、液体のりなのでノートがふやけたり、記事が破けちゃったり、のりの量が多すぎてページがくっついちゃったり…
(↑不器用にもほどがあるだろ…)
それにせっかく集めた記事でも、よっぽど管理が上手じゃ無いと
どこに何があるのかわからないですよね?
せめて「あいうえお順」または「日付順」くらいには整頓しておかないと、
多ければ多いほど、目的の記事を探すのに時間がかかることになります。
そこで思いました…
現在ならもっと簡単で検索しやすい
切り抜きの方法があるのではないかと!
と言うわけで、今回はスマホを使った
「デジタル新聞スクラップ」の作り方を紹介したいと思います。
「デジタル新聞スクラップ」作成に必要なアプリ
手順を簡単に言ってしまえば、
1. 新聞記事の写真を撮影する。
2. 記事内の文章をテキストデータに変換
3. データベースとして検索可能にする
この作業さえ完了すれば、それは立派なデジタルスクラップとなります。

これらの作業はお手持ちのスマホだけでも完結します。
そのために必要なアプリがAdobeが提供している「Adobe Scan」と「Adobe Acrobat Reader」になります。
もちろん、無料で使えます。
「Adobe Scan」と「Adobe Acrobat Reader」
今回はiOS版を紹介していますが、Android版もある様です。
「Adobe Scan」は新聞記事の撮影とテキストデータ作成に、
「Adobe Acrobat Reader」は作成したデータを管理したり、検索するために使います。
Adobeアカウントを作ります。
www.adobe.com
まず第一に、Adobeのアカウントを作ります。
↑上のリンクであらかじめ作っておいても良いですし、スマホのアプリを起動してからでも作成できます。
すでにAdobe IDをお持ちの方はそれで登録してもかまいません。
iPhoneをお持ちならApple IDと連携することもできますし、登録が楽になります。
私もApple IDと連携させて登録しました。
「Adobe Scan」を起動します。

それではAdobe Scanから起動しましょう。
読み込ませたい記事にスマホのカメラを向けます。

今回は適当に見つけた県民共済の記事の一部分を使います。
(すでに撮影済みの写真を選択したい場合は左下の写真のマークをタップして下さい。)
日本語には「縦書き」と「横書き」がありますが、
「Adobe Scan」はどちらの場合でも文字認識してくれます。
画像の指示に書いてる様に、スクリーンをタップしてみましょう。
境界線を調節して範囲を指定します。

すると、調節できる青い境界線が現れますので、
四つ角の丸いマークや長方形のマークをドラッグしながら移動させて
ちょうど文章がおさまる感じで囲んで、範囲を指定します。

↑うん、こんな感じですかね!
OKなら画面下部の「続行」をタップします。
テキストを認識しやすい様に画面のコントラストが自動調整されます。

オリジナルの写真より、コントラストが効いて文字が見やすくなります。
あらかじめ撮影した新聞記事を選択した場合は、なぜか画像だけが切り抜かれて、文字が省かれた状態で表示されたりします。
Adobeさんの自動調節は、ちょっと気を利かせすぎな時がありますので、その際は画面下部の「切り抜き」マークをタップして自分で調節して下さい。
(もしも、この自動切り抜きの解除の仕方をご存じの方は私に教えて下さい…)
準備完了なら画面右上部にある「PDFを保存」をタップします。
PDFとして保存中...

画像がPDFとして保存されます。
その後、自動的にOCR変換(テキストデータ取得)されます。
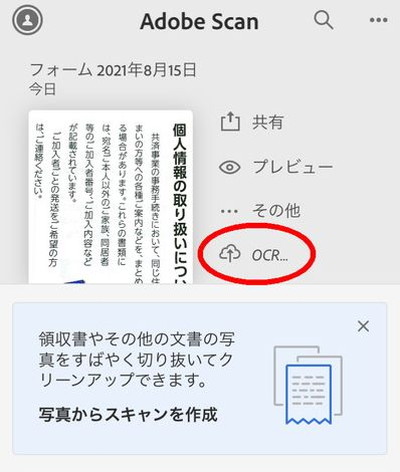
PDFとして保存される際に、OCR(Optical Character Reader)と言う文字読み取り機能により、画像内の文字がテキストデータに変換されてPDF画像ファイル内に保存されます。
通常は自動的に変換されるはずですが、もしもされてない場合は上の画像の赤枠部分をタップして下さい。
これは画像検索を可能にするために重要な作業となります。
これでテキストデータも含まれたPDF画像データが作成されました。
PDFへの保存が完了しましたら「Adobe Scan」での作業は終了です。
次に「Adobe Acrobat Reader」を開きます。

それでは「Adobe Acrobat Reader」を開きましょう。
このアプリは、これまで作成したPDFデータを検索できるようになる
いわば「データベース」の役割を担います。
こちらも「Adobe Scan」と同じくログインして使用します。
画像が「検索」できる様になっています!
「Adobe Acrobat Reader」を起動すると「Adobe Creative Cloud」と言うクラウドサーバー機能により、「Adobe Scan」で作成したデータもすでに連携されるようになっています。
画面下部の「検索」をタップすることで、作成した画像データを探すことが出来るようになります。
試しに、今回使用した記事に含まれていた「個人情報」というワードを入力してみます。

すると、このワードが含まれたPDF画像の検索結果が出て来ました。(赤枠部分)
ファイルの名前はデフォルトの状態だと「フォーム○○年○月○日」となっています。
私はこのままの状態で使ってますが、もちろん自分の好きな様に変更可能です。
それでは検索結果で出たファイルをタップしてみましょう。
画像内の文字も検索できます。

先ほどの画像が表示されました。
ここでもう一度、「個人情報」と検索してみましょう。
すると今度は、該当する部分にハイライトが当てられます。
OCRによりテキストとして認識されているのがわかりますね。
OCRで変換された全テキストを確認するには?
その画像データ内にあるOCRで変換した全テキストデータを確認する場合は、
もう一度「Adobe Scan」に戻って下さい。
目的のファイルを開いたら、まずは画面下部にある「テキストアクション」と言う項目をタップします。

すると、テキストとして認識されている箇所にハイライトが当てられます。
次に「テキストをコピー」をタップすることで、変換したテキストデータがコピーされます。
あとは、メモアプリ等にペーストします。
注意!全てのテキストが100%正確に変換されてるワケではないです。

ここで一つ注意していただきたいのは、
OCRで変換したテキストは100%正確に変換されるワケではない!
と言う事です。
例えば、上の画像を見ても、ある程度は正確に変換されていますが、
最後のあたりは文字化けと言っても良い部分があります。
と言っても、この場合はイラスト部分の何かの記号まで変換したせいではありますが…
特に、新聞を撮影した場合は光の加減や影により、読み込まれなかったり誤変換が起きる可能性があります。
これはまだ技術の限界と言える部分かも知れません。
ただ、ほとんどの場合は記事内の重要なキーワードはしっかり変換されています。
なので「検索用のテキスト変換」として割り切ると十分及第点だと思います。
これで検索も簡単に出来るデジタル新聞スクラップの完成です。
あとはこの作業を繰り返して、自分だけのオリジナルスクラップを作成していきましょう!!
デジタルスクラップのメリット
今回紹介した方法で作成するデジタルスクラップのメリットを紹介します。
・単語検索ができる!
これは何よりも最大のメリットだと思います。
新聞紙を実際に切り貼りしたスクラップでも、スマホで撮った画像だけでもできない事がこの「単語で検索すること」なのです。
画像内の文字がテキストデータに変換されて、画像データ内に含まれてるので検索が簡単なのです。
データ自体にも作成した日付が記録されていますので、いつ頃作成したかも一目瞭然です。
少しだけ手間はかかりますが、そこさえクリアすれば後は簡単に目的のデータを見つけられますね!
・データが劣化しない
これもデジタルならではの恩恵ですね!通常の新聞スクラップではどうしても経年劣化と言うのは避けられません。色あせたり、中には触っただけでボロボロになる場合もあります。
スマホで1度撮影した写真は、それ以上風化することもありません。
・複数のデバイスで確認できる
iPadやiPhone、PCやその他のデバイスに「Adobe Acrobat Reader」をインストールし、共通のAdobeアカウントを登録しておけば、同じデータを複数の機器で閲覧することが出来ます。
言うなれば、スクラップを1度作っただけで5個も6個も製作した事になります。
これは便利過ぎます!
・バックアップも可能
今回製作したデータは「Adobe Creative Cloud」と言うクラウドサーバーに保存される事になります。
無償ユーザーでもストレージ2GBまでは利用できます。画像を1MBくらいと考えると、無料で2000枚くらいまでは保存できます。これはかなりの数です。
PC版「Adobe Creative Cloud」を使えばバックアップもできる様になりますし、
PC版「Adobe Acrobat Reader」では特定のファイルを選んで好きな場所にコピーも簡単にできます。万が一、自分が使っていたデバイスを紛失したり、破損させても別なデバイスで見る事も簡単なのです。
・無料でできる
無料でできちゃう事、これも重要ですね!
クラウドサーバーはストレージが2GBまで使えますが、個人だと容量的に十分だと思いますし、もしも足りないと言う方は月額1,078 円で1TBまで使用できる様になります。
クラウドサーバーを使わないし、PCでしか使わないと言う方はPC版「Adobe Acrobat Reader」でデータを自分のPC内で保存すればずっと無料で使えます。
まとめ:「Adobe Scan」&「Adobe Acrobat Reader」なら情報収集も検索も簡単です!
今回は「スマホでできるデジタル新聞スクラップの作り方」と題して、
「Adobe Scan」と「Adobe Acrobat Reader」の使い方を紹介しました。
私もこのデジタルスクラップをやり始めて一ヶ月くらいになります。
この作業を続けて思ったのは、
ブログを作る際のネタ集めが
少し楽になった感じがする
と言う事です。
今までは、ほとんどインターネットの記事だけを中心にブログを作って来ましたが、
自分が読んでいる新聞にも面白い事ってたくさん書かれてるんですよね。
ただ、これまでは新聞記事を何らかの手段で残そうと言う気もありませんでしたし、
自分もかなり忘れっぽい性格なので、せっかく読んでも情報を上手く活用できませんでした。
最近はスマホ片手に新聞を読んでいて、気に入った記事があればパシャっと撮って、
データベースとして活用しています。
もちろん、新聞だけじゃなく雑誌でもこの方法は使えます!
もしもご興味がありましたら、1度試してみて下さい!
特に小説を書いている個人作家さんには、かなり有効な情報収集の方法だと思います。
以上です…













")




























")
")
")
")













(スマプラ対応) 通常盤(初回盤終了)")